
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- dockerfile
- 창업 마인드
- java Optional
- AWS 키페어
- 자바 스트림
- AWS 프로젝트 올리기
- vscode
- CI/CD
- AWS ssh
- AWS S3
- AWS EC2
- 스트림 예제
- @async
- Visual Studio Code
- AWS
- spring multi thread
- github CI/CD
- java stream
- 창업형인간
- 마인드
- AWS 프로젝트
- optional
- 창업형인간되기
- Optional 사용법
- 비주얼 스튜디오 코드
- spring async
- ssh
- 라이프해킹스쿨
- 창업
- java null 처리
- Today
- Total
Wookim
큐피스트 면접 질문 본문
대답 못한 질문들을 찾아 정리해보았다.
내용은 굉장히 단순화해서 정리했고
부정확한 내용도 있을 수 있다.
대충 뭔지 한번 알고 싶을 때 읽어보고,
참고한 내용의 글들을 읽어보면
이해가 더 빠르지 않을까 싶다.
라운드 로빈 알고리즘
로빈이라는 새의 이름을 딴 알고리즘으로
운영체제 스케줄링에 사용되는 알고리즘이라고 한다.
로빈이라는 새는 자식들에게 먹이를 조금씩 분할해 먹이를 나눠주는데
자식들이 10마리라 하면 먹이를 공평하게 나눠준다.
1번새끼가 먹었다면 2번을 2번이 먹으면 3번을... 쭉 돌아
10번까지 먹었다면 다시 1번부터 밥을 주는식으로
공평하게 먹이를 나눠준다고 한다.
이점에서 착안하여 이름을 붙힌것으로 예상한다.
cpu와 os는 위 알고리즘을 이용해 작업 사항들이 예약이 되면 비슷한 맥락으로
특정량 만큼 작업을 실행하고, 다 마치지 못했다 해도 예약된 다음 작업으로 변경해 같은 양만큼 작업을 실행한다.
이를 콘텍스트 스위칭 이라고 한다.
그렇게 모든 작업들을 한번 순회하고 나서
다시 마치지 못한 첫번째 작업으로 돌아와 실행하고 같은 작업를 반복한다.
다만 콘텍스트 스위칭이 자주일어나면 부하가 발생한다.
따라서 한번에 처리하는 양이 중요하다.
cpu burst와 time
cpu burst라는 용어가 등장하는데 시퓨가 명령을 실행하는 것이라고 한다.
cpu burst time이라면 실행하는데 걸리는 시간이라 생각된다.
cpu burst time의 80%을 차지할수있는 시간을 설정하라는 원칙이있다 (rule of thumb)
얼핏 보면 병렬적으로 작업이 된다고 착각하게 만드는 것 같다.
(병렬적이지 않다!)
참고한 글 https://jhnyang.tistory.com/158
[운영체제]RR(Round Robin라운드로빈)순환할당스케줄링, time quantum 타임퀀텀
[운영체제 목차 책 추천] Round Robin (RR) Algorithms 이번에 살펴볼 스케줄링 알고리즘은 RR입니다. 이 포스팅을 보기 전에 스케줄링 게시글을 읽고 오기를 권장해요 사실 time sharing system(시분할 시스템
jhnyang.tistory.com
무중단 DB 데이터 이관 시 데이터 싱크를 맞추는 방법은?
질문
A라는 서버가 있고 사용중인 DB는 A-DB이다.
해당 A서버를 다른 프로그램 언어로 재개발한 서버와 다른 DB를 사용하려한다.
A서버 -> B서버 변경
A-DB -> B-DB 변경
문제는 A서버와 DB는 내리지 않고 B서버와 DB로 데이터를 이관하고 싶다.
A서버는 서비스를 계속 제공하고 새 서버 B는 데이터를 싱크를 맞추며 이관받아야 한다.
어떻게 해야할까?
나는 새 프로젝트를 개발해 처리할것 같다고 이야기했다.
새 프로젝트 : 데몬 프로그램, C-DB 사용
1. A-DB -> B-DB 로 데이터 이관하는 쿼리 실행
2. A-DB로 들어오는 CRUD 메세지들을 C-DB에 저장
3. 1번 작업이 완료되면 C-DB에 저장된 메세지들을 B-DB에 실행하여 싱크 맞추기
이렇게 대답했는데, 해당 회사에서는 카프카를 이용해 처리한다고 했다.
들어본적 있는 단어지만 뭔지는 전혀 몰랐다.
그래서 카프카에 대해 찾아보고 내 생각을 정리해보았다.
카프카와 메세지 큐
자세히 다루기보단 대충 뭔지 감이라도 잡아보자
카프카
카프카는 쉽게 생각하자면 메세지 큐다.
조금더 보태자면 큐를 여러개를 만들어 각각에 메세지를 저장하고 소비한다.
큐 ----> 소비자1
작성자 큐 -------^
큐 ----> 소비자2
큐 ----> 소비자 3
메세지 큐를 수평적으로 여러개 만들고 메세지를 저장할 때 라운드로빈 알고리즘을 이용해 분산 저장한다.
(메세지 하나를 나눠서 저장하는게 아니라 메세지들을 각기 다른 큐에 분산하여 저장하는것)
소비할때는 소비자를 여러개 만들어 하나의 메세지큐에 하나의 소비자가 1:1 매칭 되도록 설정한다.
작성자를 퍼블리셔
소비자를 컨슈머라고 한다
왜 하나의 큐가 아니라 여러개의 큐로 분산 저장할까?
하나의 큐에 엄청난 메세지가 쏟아질 경우 큐에 해당 메세지를 저장할때 과부하가 걸릴수도 있다. (단일 스레드)
이 때 멀티스레드로 다른 큐에 저장하도록 프로그래밍되면 빠르게 저장을 할수 있을 것이라 예상한다.
(예상 : 멀티스레드와 독립된 저장공간 혹은 멀티스레드와 독립된 저장공간 활용)
대규모 프로젝트의 트래픽처리를 위해 설계된것으로 예상한다.
그렇기에 큐를 여러개로 나누고 각각에 로그(데이터)를 분산 저장한다.
그리고 소비자가 뻗는 장애현상 시 빠르게 대처하기위한 구조라고 한다.
즉 소비자가 뻗었다면 다른 소비자가 해당 큐를 소비하도록 설정하는것.
이때 뻗기 전 소비자가 읽던 로그의 위치를 알수 있기에(소비자 끼리 공유한다고 함)
정확한 위치의 메세지를 소비할수 있다고 한다.
내가 이해한 내용을 정리하자면
1. 카프카는 메세지 큐다
2. 여러개의 큐로 구성되며, 저장할 때 분산 저장한다. (순서가 필요없는 경우에 용이하다)
3. 메세지 저장 시 부하가 예상될 때 사용한다.
4. 메시지 소비 시 부하가 예상될 때 사용한다.
5. 여러 장애현상을 대비할수 있다.
참고한 글
Kafka 이해하기
카프카의 구성요소, 동작원리, Exactly-delivery-once 모델 차용
medium.com
멀티 프로세스와 멀티 스레드의 차이는?
프로세스란?
처리 과정이다.
컴퓨터의 프로세스
1. os로 부터 자원을 할당받는 "작업단위"
2. 컴퓨터에서 연속적으로 실행되고 있는 프로그램
3. 메모리에 올라와 실행되고 있는 프로그램의 인스턴스
참고한 글의 필자는 크레이지 아케이드 게임에 빗대어 표현함
물풍선을 놓는다
물풍선이 터진다
시간이 간다
벽이 부셔진다
(맞는 표현인지는 모르겠다)
와 같이 하나의 작업 모두 프로세스이다.
그리고 하나 하나 프로세스가 각각 독립적으로 진행되는것 같지만
사실 cpu가 스케줄에 의해 작업을 진행한다. 위에 RR 알고리즘을 이용해서.
즉 작업과 작업사이 콘테스트 스위칭이 발생하고 이는 부하가 된다.
(증복된 자원, 비효율)
이를 해결하기 위한것 - 멀티스레드
스레드란?
한 프로세스 내에서 동작되는 여러 실행의 흐름
프로세스 하나에 자원을 공유하면서 일련의 과정을 여러개를 동시에 실행 시킬수 있는 것
1. 한 프로세스 내의 주소 공간이나 자원들을 대부분 공유
2. 기본적으로 하나의 프로세스가 생성되면 하나의 스레드도 같이 생성
3. 이를 메인 스레드라 부르며 스레드를 추가하지 않으면 이 메인 스레드에서 모든 코드를 실행함
4. 하나의 프로세스는 여러개의 스레드를 가질수 있고 이를 멀티 스레드라함
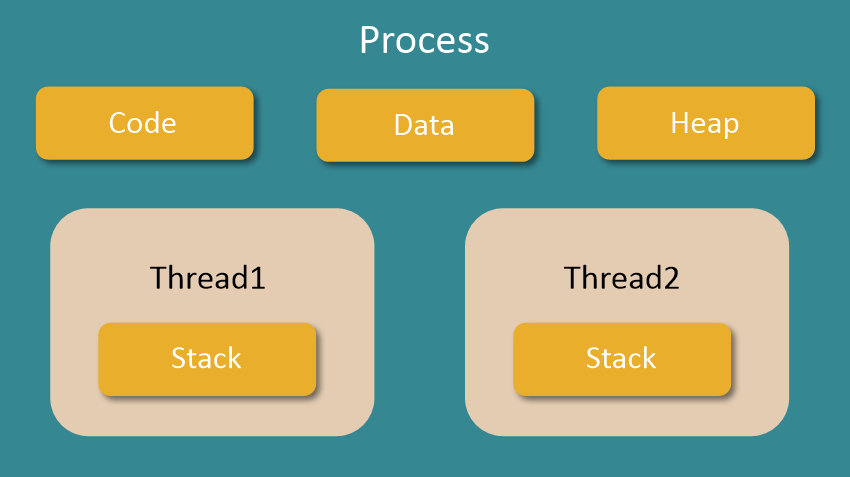
[OS]프로세스(Process)와 스레드(Thread)의 차이/멀티 프로세스와 멀티 스레드의 개념 ,특징, 장단점
[OS] 프로세스(Process)와 스레드(Thread)의 차이/멀티 프로세스와 멀티 스레드의 개념 , 특징, 장단점 1. 프로세스(Process)와 스레드(Thread) 먼저, 프로세스(process) 란 무엇일까? 프로세스는 단순하게 말
devuna.tistory.com
멀티 프로세스는
장 : os에 여러 프로세스를 독립적으로 띄워 각각의 프로세스간 충돌문제가 없어 안정적이다
단 : 자원의 낭비, 컨텍스트 스위치로인한 오버헤드
멀티 스레드는
장
응답속도 증가
시스템의 처리속도 향상
자원 소모 감소 (공유)
멀티 프로세스간 통신보다 스레드간 통신이 더 간단
단
여러개의 스레드일 경우 미묘한 시간차나 잘못된 데이터가 존재 할 경우 이를 공유함
* 스레드간 통신 시 출동문제 없도록 동기화 문제 해결 필요
단일 프로세스 시스템에서는 기대효가 없음
참고한 글 https://devuna.tistory.com/21
[OS]프로세스(Process)와 스레드(Thread)의 차이/멀티 프로세스와 멀티 스레드의 개념 ,특징, 장단점
[OS] 프로세스(Process)와 스레드(Thread)의 차이/멀티 프로세스와 멀티 스레드의 개념 , 특징, 장단점 1. 프로세스(Process)와 스레드(Thread) 먼저, 프로세스(process) 란 무엇일까? 프로세스는 단순하게 말
devuna.tistory.com
결과는 불합받았따. ㅠ
면접내내 질문에 대해 동문서답한 것도 있고
잘모르는 내용들이 너무 많았다.
그냥 몰라요 이렇게 대답하기보다
잘은 모르지만 이렇게 생각합니다 라는 식으로 진행했는데,
부족한점이 내가봐도 너무 많았다...
그래도 좋은 경험했다.
면접은 CTO와 1:1로 진행했는데
1시간 30분정도 진행했다.
조곤조곤 이야기해주시고
경청해주시는 태도가 좋았다.
마지막에 궁금한게 있냐고 물어보셨는데,
나는 내가 대답못한 것들을 여쭤봤는데
친절하게 알려주셨다.
그래서 카프카니 뭐니 하는 것들을 이번에 조사해봤다.
확실히 면접보고나서 내가 뭐가 부족한지 조금은 알게되었다.
지금은 프로젝트를 AWS에 올리고
devops 작업을 진행중에 있다.
하던 것들을 잘 정리해서 다음 면접기회가 오면
어필할수 있길...